
Gmail RAG Pipeline
Architecture Diagram
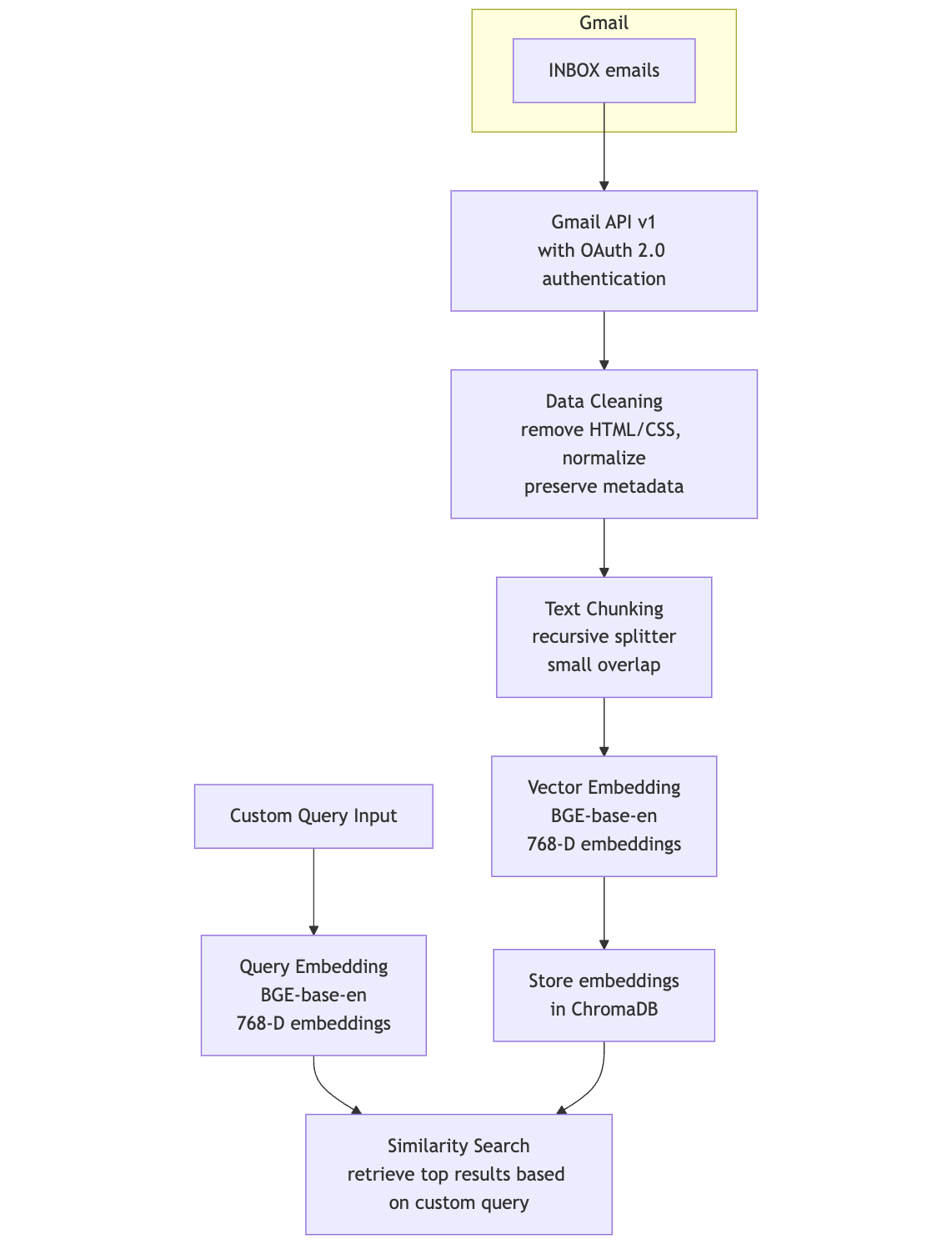
Introduction
This project creates an end-to-end Retrieval-Augmented Generation (RAG) pipeline for Gmail data, enabling semantic search and retrieval over email content. The pipeline fetches and cleans emails, chunks them into searchable segments, embeds the chunks, and stores them in a vector database for efficient querying.
Workflow
The workflow has six main steps:
- Data Ingestion: Fetch emails from Gmail using the Gmail API with OAuth 2.0 authentication and Base64 decoding.
- Data Cleaning: Process email text to remove HTML and CSS, normalize content, and keep original metadata intact.
- Text Chunking: Split cleaned content into overlapping character chunks to improve retrieval context.
- Vector Embedding and Storage: Create embeddings using the BGE-base-en model for high-quality 768-dimensional embeddings.
- Vector Database: Store embeddings in ChromaDB (a vector database) for fast and accurate similarity search.
- Query Interface: Search stored embeddings to find the most relevant email chunks according to a given prompt.
The system automates the flow from Gmail inbox to vectorized semantic search and is designed to be modular and easy to extend.
Technologies:
Python Gmail API OAuth 2.0 LangChain Ollama Llama3 ChromaDB Hugging Face Transformers
Concepts / Algorithms:
RAG Vector embeddings Semantic search Text chunking Email parsing LLM inference Embedding-based retrieval